I am Michael Firman, a Senior Staff Research Scientist at Niantic Spatial, where I work on machine learning and computer vision to help people explore and understand the world around them.
At Niantic, I’ve led both research and engineering efforts that bring advanced 3D perception to production; from depth estimation, 3D reconstruction, semantics, and AR occlusion to the infrastructure and evaluation systems that make large-scale deployment possible. My work bridges academic research and real-world systems.
Previously, I was a postdoctoral researcher in UCL’s Vision and Graphics group on the Engage project, making machine learning tools accessible to scientists across different disciplines. I collaborated with Prof. Mike Terry (University of Waterloo), Dr. Gabriel Brostow (UCL), and Prof. Kate Jones (UCL). During the summer of 2012, I worked at the National Institute of Informatics, Tokyo with Prof. Akihiro Sugimoto.
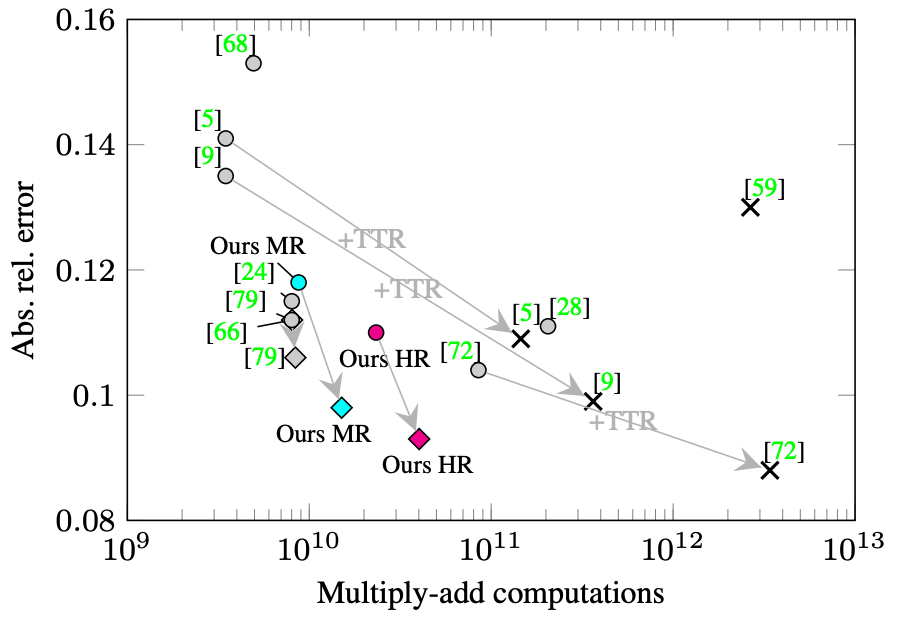
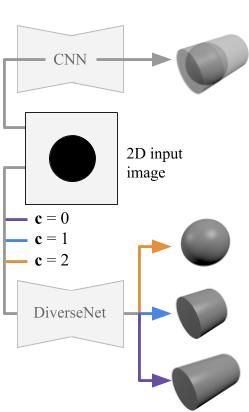
My PhD, supervised by Dr. Simon Julier and Dr. Jan Boehm, explored how to complete full 3D scenes from single depth images — an early contribution to geometric scene understanding with applications in robotics, computer graphics, and augmented reality.
I have published at leading venues including CVPR, ICCV, IROS, and ECCV, and have served as a reviewer for CVPR, ECCV, ICCV, IROS, BMVC, ICRA, IJCV, CVIU, 3DV, and ISMAR. I received CVPR’s Outstanding Reviewer award in 2018, 2020, 2022, and 2025.