I am Michael Firman, a staff research scientist at Niantic, Inc., where I work on machine learning and computer vision research to help people explore the world around them.
Previously, I worked at UCL in the Vision and Graphics group as a postdoc on the Engage project, making machine learning tools accessible to scientists across different disciplines. This work was with Prof. Mike Terry at the University of Waterloo, Dr. Gabriel Brostow at UCL and Prof. Kate Jones at UCL.
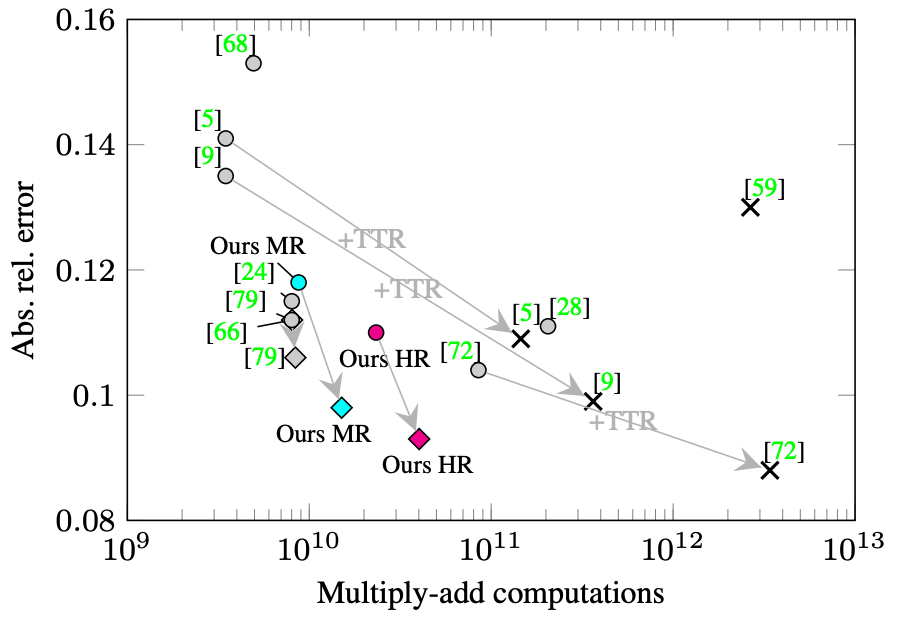
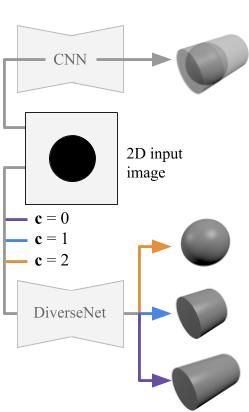
My PhD was supervised by Dr. Simon Julier and Dr. Jan Boehm. During my PhD I predominantly worked on the problem of inferring a full volumetric reconstruction of a scene, given only a single depth image as input. This problem has many applications in robotics, computer graphics and augmented reality.
During the summer of 2012 I worked at the National Institute of Informatics, Tokyo, under the supervision of Prof. Akihiro Sugimoto.
I have also served as a reviewer for CVPR, ECCV, ICCV, IROS, BMVC, ICRA, IJCV, CVIU, 3DV and ISMAR. I received CVPR's `outstanding reviewer' award in 2018, 2020, 2022 and 2025.